
Table of Contents
Last update on
Robots.txt is a powerful server file that tells search crawlers and other bots how to behave on your WordPress website. It can greatly influence your site’s search engine optimization (SEO), both positively and negatively.
For that reason, you should know what this file is and how to use it. Otherwise, you could damage your website or, at least, leave some of its potential on the table.
To help you avoid this scenario, in this post, we’ll cover the robots.txt file in detail. We’ll define what it is, its purpose, how to find and manage your file, and what it should contain. After that, we’ll go over the most common mistakes people make with their WordPress robots.txt, ways to avoid them, and how to recover if you find you’ve made an error.
What Is the WordPress robots.txt?
As mentioned, robots.txt is a server configuration file. You usually find it in the root folder of your server.
When you open it, the content looks something like this:
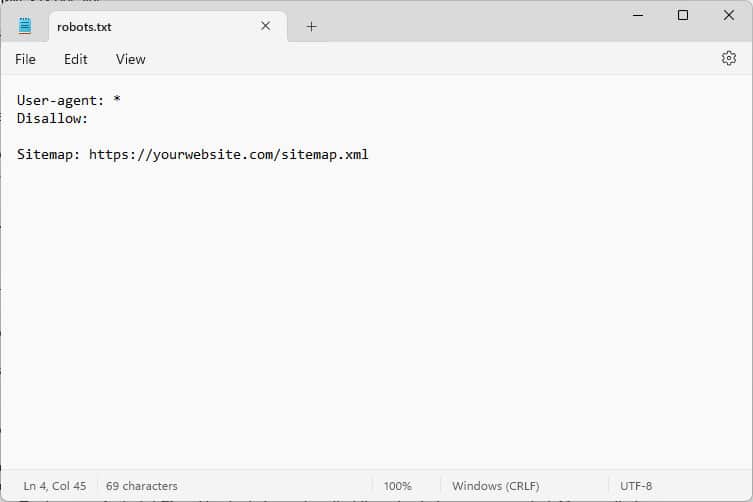
These pieces of code are instructions that tell bots who come to your website how to conduct themselves while they are there—specifically, which parts of your website to access and which not.
What bots, you ask?
The most common examples are automatic crawlers from search engines looking for web pages to index or update, but also bots from AI models and other automated tools.
What Directives Can You Give With This File?
Robots.txt basically knows four key directives:
- User-agent – Defines who, meaning which group of or individual bots the rules that follow are for.
- Disallow – States the directories, files, or resources the user-agent is forbidden from accessing.
- Allow – Can be used to set up exceptions, e.g., to allow access to individual folders or resources in otherwise forbidden directories.
- Sitemap – Points bots to the URL location of a website’s sitemap.
Only User-agent and Disallow are mandatory for the file to do its job; the other two directives are optional. For example, this is how you block any bots from accessing your site:
User-agent: *
Disallow: /The asterisk denotes that the following rule applies to all user agents. The slash after Disallow states that all directories on this site are off limits. This is the robots.txt file you usually find on development sites, which are not supposed to be indexed by search engines.
However, you can also set up rules for individual bots:
User-agent: Googlebot
Allow: /private/resources/It’s important to note that robots.txt is not binding. Only bots from organizations that adhere to the Robots Exclusion Protocol will obey its directions. Malicious bots, such as those that look for security flaws on your site, can and will ignore them, and you need to take additional measures against them.
Even organizations that adhere to the standard will ignore some directives. We’ll talk about examples of that further below.
Why Does robots.txt Matter?
It’s not mandatory for your WordPress site to have a robots.txt file. Your site will function without one, and search engines won’t penalize you for not having it. However, including one allows you to:
- Keep content out of search results, such as login pages or certain media files.
- Prevent search crawlers from wasting your crawl budget on unimportant parts of your site, possibly ignoring pages you want them to index.
- Point search engines to your sitemap so they can more easily explore the rest of your website.
- Preserve server resources by keeping wasteful bots out.
All of this helps make your site better, particularly your SEO, which is why it matters that you understand how to use robots.txt.
Here’s what Benjamin Denis, Founder of SEOPress, says about robots.txt value:
The robots.txt file is often overlooked, yet it’s one of the first things search engines look at when crawling your site. A misconfigured file can unintentionally block important pages or resources, negatively affecting your SEO. Instead of using it to hide content, think of it as a way to optimize crawl budget—prioritize what truly matters. When used correctly, it complements your overall SEO strategy.
How to Find, Edit, and Create Your WordPress robots.txt
As mentioned, robots.txt usually lies in your website’s root folder on the server. You can access it there with an FTP client like FileZilla and edit it with any text editor.
If you don’t have one, it’s possible to simply create an empty text file, name it “robots.txt”, fill it with directives, and upload it.
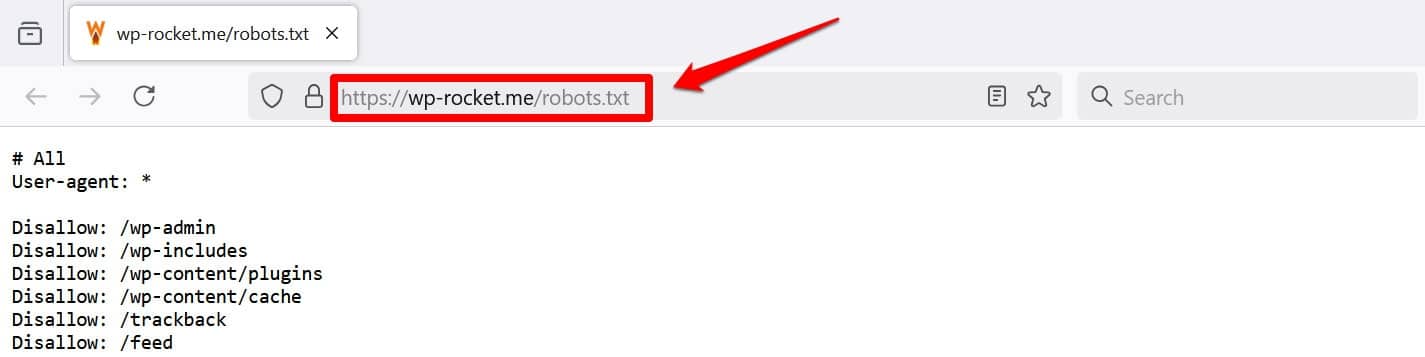
Another way to at least view your file is to add /robots.txt to your domain, e.g., https://wp-rocket.me/robots.txt.
In addition, there are ways to access the file from the WordPress back end. Many SEO plugins allow you to see and often make changes to it from the administration interface.
Alternatively, you can also use a plugin like WPCode.
What Does a Good WordPress robots.txt File Look Like?
There’s no one-size-fits-all answer to what directives should be in your website’s file; it depends on your setup. Here is an example that makes sense for many WordPress websites:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://yourwebsite.com/sitemap.xmlThis example achieves several outcomes:
- It blocks access to the admin area
- Allows access to essential admin functionality
- Provides a sitemap location
This setup strikes a balance between security, SEO performance, and efficient crawling.
Don’t Make These 14 WordPress robots.txt Mistakes
If your goal is to set up and optimize the robots.txt for your own site, be sure to avoid the following errors.
1. Ignoring the Internal WordPress robots.txt
Even if you don’t have a “physical” robots.txt file in your site’s root directory, WordPress comes with its own virtual file. That’s especially important to remember if you find that search engines are not indexing your website.
In that case, there’s a good chance that you’ve enabled the option to discourage them from doing so under Settings > Reading.
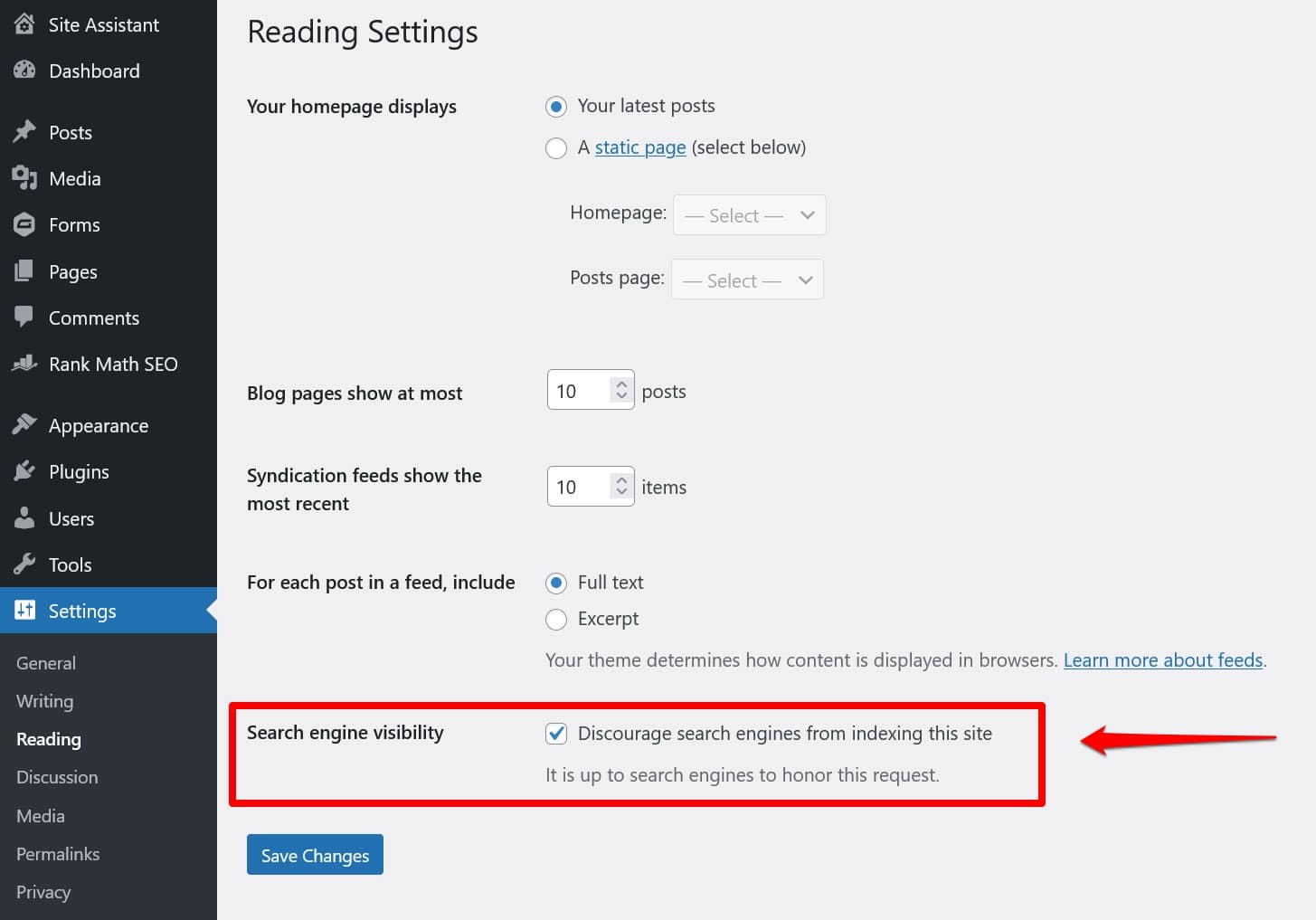
This puts a directive to keep all search crawlers out in the virtual robots.txt. To disable it, uncheck the box and save it at the bottom.
2. Placing It in the Wrong Location
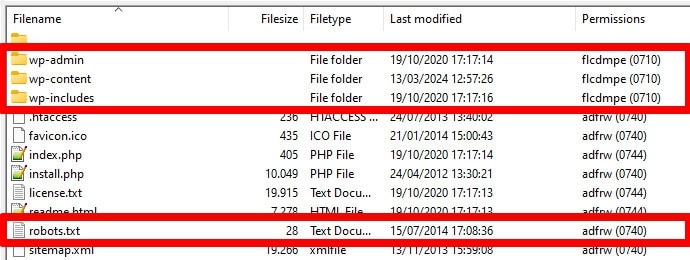
Bots, particularly search crawlers, look for your robots.txt file only in one location—your website’s root directory. If you place it anywhere else, such as in a folder, they will not find it and will ignore it.
Your root directory should be where you land when you access your server via FTP, unless you’ve placed WordPress in a subdirectory. If you see the wp-admin, wp-content, and wp-includes folders, you are in the right place.
3. Including Outdated Markup
Besides the directives mentioned above, there are two more that you might still find in older websites’ robots.txt files:
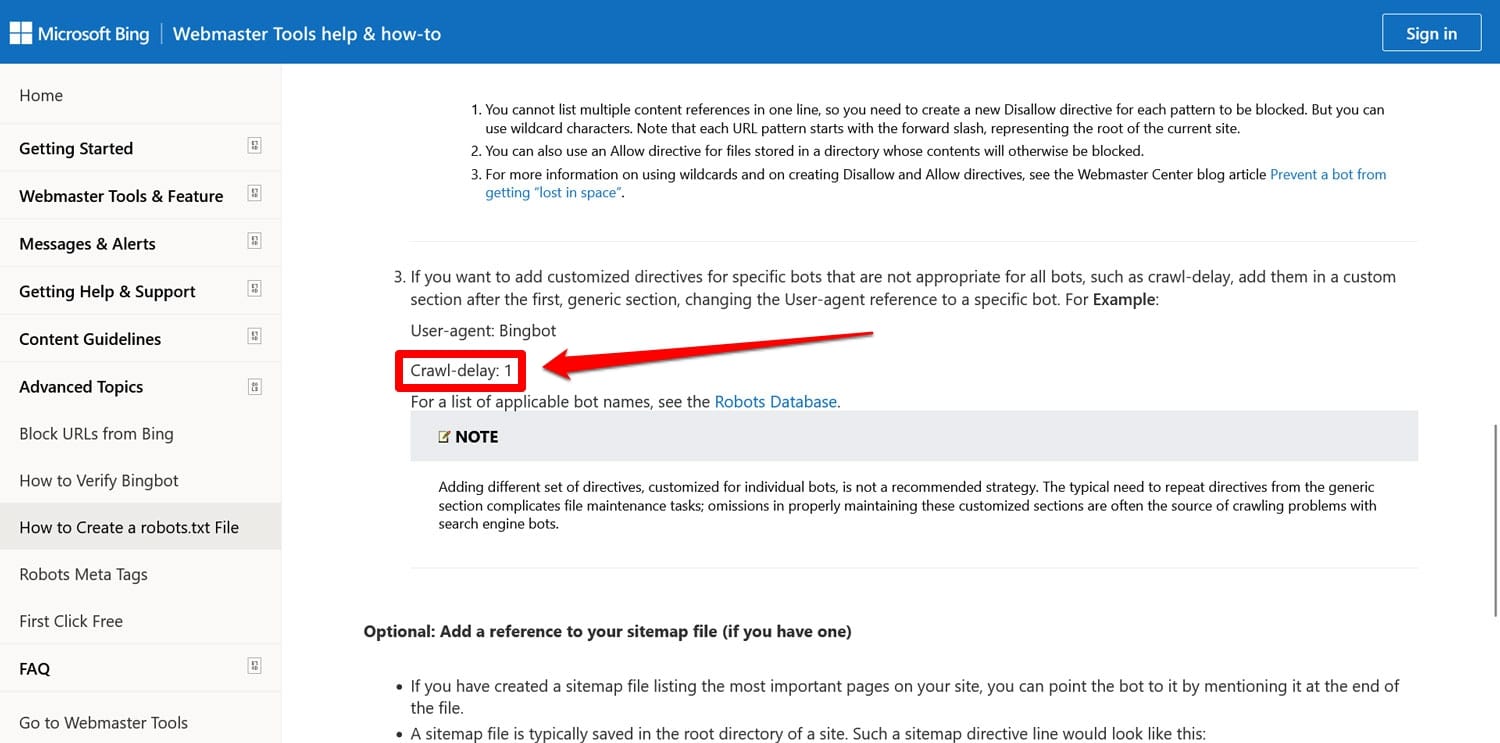
- Noindex – Used to specify URLs that search engines are not supposed to index on your site.
- Crawl-delay – A directive meant to throttle crawlers so they don’t overload web server resources.
Both of these directives are now ignored, at least by Google. Bing, at least, still honors crawl-delay.
For the most part, it’s best not to use these directives. This helps keep your file lean and reduces the risk of errors.
💡Tip: If your goal is to keep search engines from indexing certain pages, use the noindex meta tag instead. You can implement it with an SEO plugin on a per-page basis.
If you block pages via robots.txt, crawlers won’t get to the part where they see the noindex tag. That way, they may still index your page but without its content, which is worse.
4. Blocking Essential Resources
One of the mistakes people make is using robots.txt to block access to all style sheets (CSS files) and scripts (JavaScript files) on their WordPress site to preserve the crawl budget.
However, that’s not a good idea. Search engine bots render pages to “see” them the same way visitors do. This helps them understand the content so they can index it accordingly.
By blocking these resources, you could give search engines the wrong impression of your pages, potentially leading them not to be indexed properly or hurting their ranking.
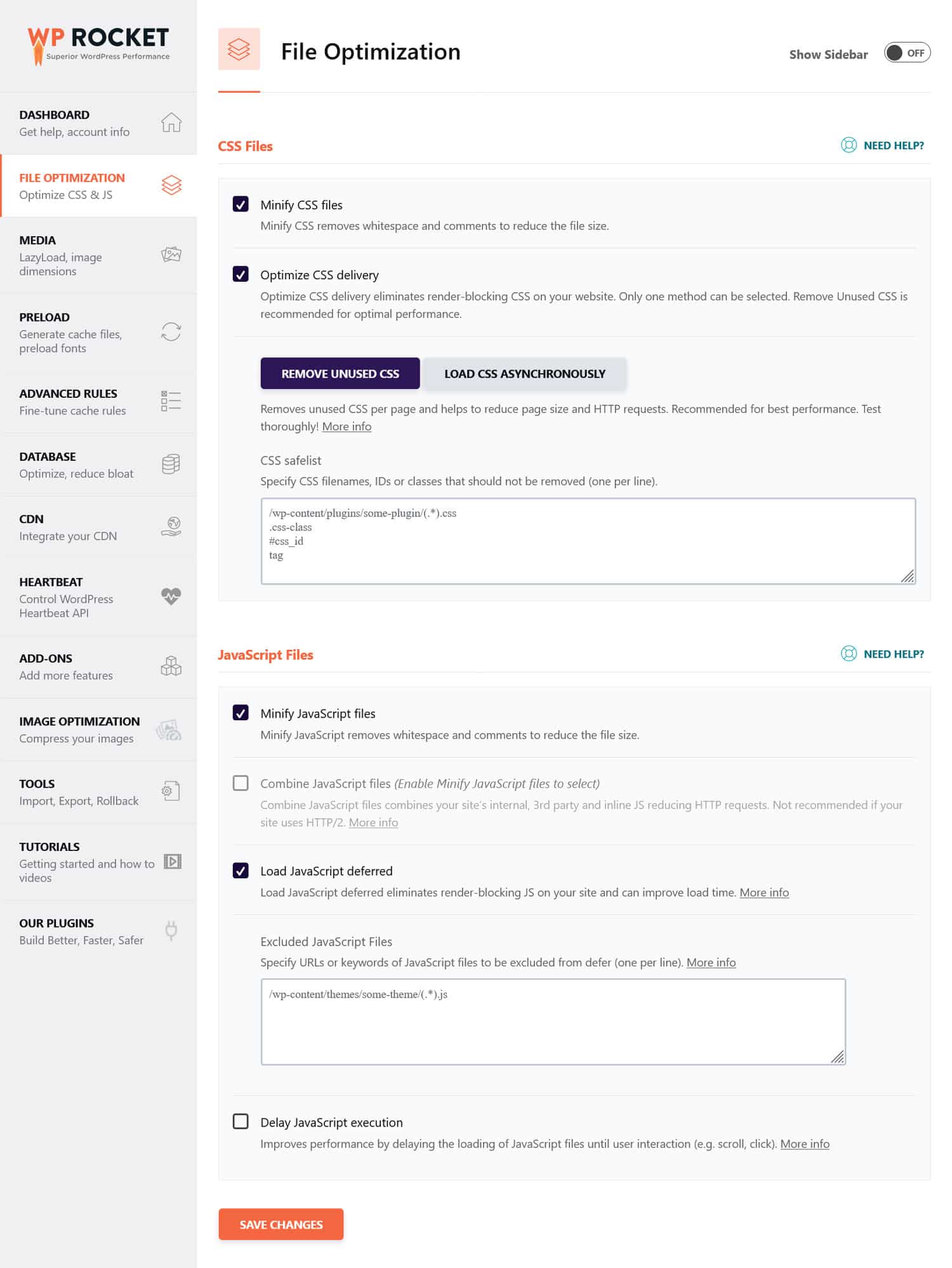
If you think CSS and JavaScript files might impede your site’s performance, it’s a better idea to optimize them to load quickly, both for bots and regular visitors. You can do so by minifying code and compressing website files so they transmit faster. In addition, it’s possible to optimize their delivery by eliminating unused code and deferring render-blocking resources.
💡 Tip: You can simplify this process by using a performance plugin like WP Rocket. Its user-friendly interface allows you to optimize file delivery by checking a few boxes in the File Optimization menu.
WP Rocket also comes with additional features to improve website performance, including:
- Caching, with a dedicated mobile cache
- Lazy loading for images and videos
- Preloading cache, links, external files, and fonts
- Database optimization
Additionally, the plugin implements many optimization steps automatically. Examples include browser and server caching, GZIP compression, and optimizing images above the fold to improve LCP. That way, your site will get faster simply by switching WP Rocket on.
The plugin also offers a 14-day money-back guarantee, so you can test it risk-free.
5. Failing to Update Your Development robots.txt
When building a website, developers typically include a robots.txt file that forbids all bots from accessing it. This makes sense; the last thing you want is for your unfinished site to show up in search results.
A problem only occurs when you accidentally transfer this file to your production server and block search engines from indexing your live website as well. Definitely check this if your content refuses to appear in search results.
6. Not Including a Link to Your Sitemap
Linking to your sitemap from robots.txt provides search engine crawlers with a list of all your content. This increases your chances they’ll index more than just the current page they have landed on.
All it takes is one line:
Sitemap: https://yourwebsite.com/sitemap.xmlYes, you can also submit your sitemap directly in tools like Google Search Console.
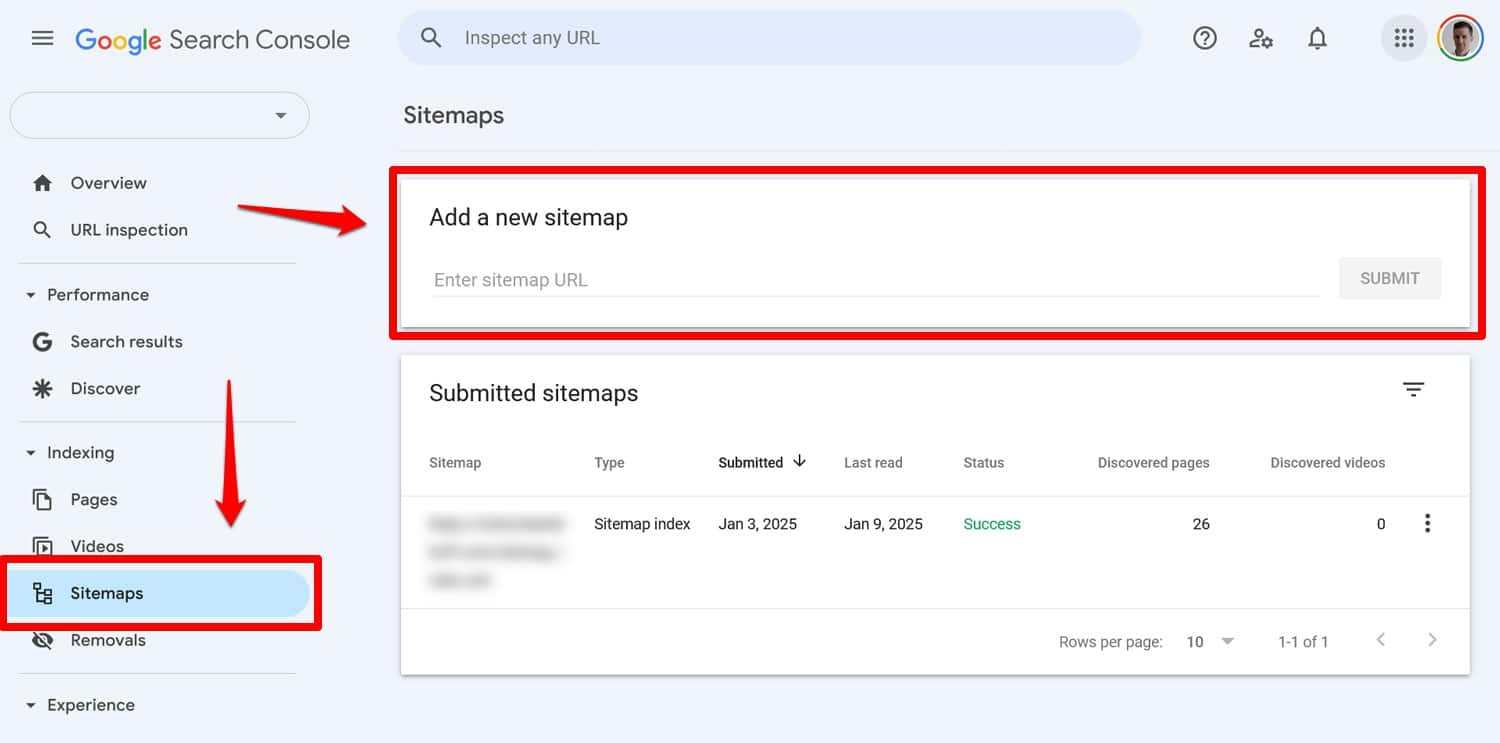
However, including it in your robots.txt file is still useful, especially for search engines whose webmaster tools you are not using.
7. Using Conflicting Rules
One common mistake in creating a robots.txt file is adding rules that contradict each other, such as:
User-agent: *
Disallow: /blog/
Allow: /blog/The above directives leave search engines unclear on whether they should crawl the /blog/ directory or not. This leads to unpredictable results and can damage your SEO.
| 📖 Curious what else can be detrimental to your site’s search rankings and how to avoid it? Learn about it in our guide to SEO mistakes. |
To avoid conflicts, follow these best practices:
- Use specific rules first – Place more specific rules before broader ones.
- Avoid redundancy – Don’t include opposing directives for the same path.
- Test your robots.txt file – Use tools to confirm that the rules behave as expected. More on that below.
8. Trying to Hide Sensitive Content With robots.txt
As previously mentioned, robots.txt is not a tool to keep content out of search results. In fact, because the file is publicly accessible, using it to block sensitive content may inadvertently reveal exactly where that content is located.
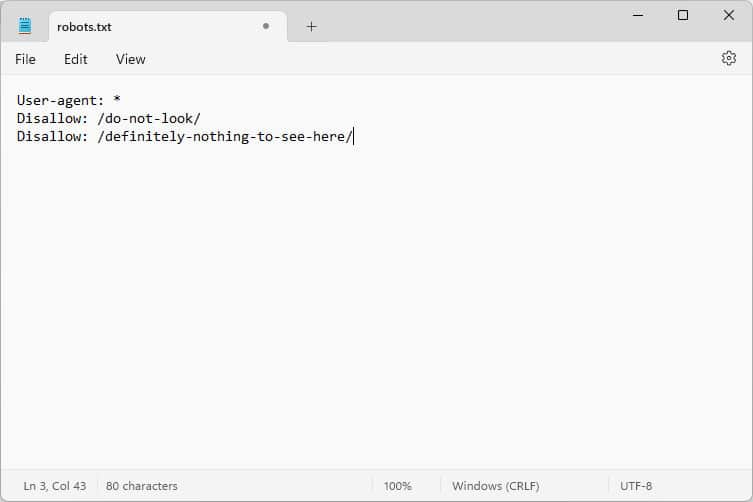
💡Tip: Use the noindex meta tag to keep content out of search results. Additionally, password-protect sensitive areas of your site to keep them safe from both robots and unauthorized users.
9. Improperly Employing Wildcards
Wildcards allow you to include large groups of paths or files in your directives. We’ve already met one earlier, the * symbol. It means “every instance of” and it is most frequently used to set up rules that apply to all user agents.
Another wildcard symbol is $, which applies rules to the end part of a URL. You can use it, for example, if you want to block crawlers from accessing all PDF files on your site:
Disallow: /*.pdf$While wildcards are useful, they can have wide-reaching consequences. Use them carefully, and always test your robots.txt file to ensure you didn’t make any mistakes..
10. Confusing Absolute and Relative URLs
Here’s the difference between absolute and relative URLs:
- Absolute URL – https://yourwebsite.com/private/
- Relative URL – /private/
It’s recommended that you use relative URLs in your robots.txt directives, for example:
Disallow: /private/Absolute URLs can cause issues where bots may ignore or misinterpret the directive. The only exception is the path to your sitemap, which needs to be an absolute URL.
11. Ignoring Case Sensitivity
Robots.txt directives are case-sensitive. This means the following two directives are not interchangeable:
Disallow: /Private/
Disallow: /private/If you find that your robots.txt file isn’t behaving as expected, check whether incorrect capitalization could be the issue.
12. Using Trailing Slashes Incorrectly
A trailing slash is a slash at the end of a URL:
- Without a trailing slash: /directory
- With a trailing slash: /directory/
In robots.txt it decides which site resources are allowed and disallowed. Here’s an example:
Disallow: /private/The above rule blocks crawlers from accessing the “private” directory on your site and everything in it. On the other hand, let’s say you leave out the trailing slash, like so:
Disallow: /privateIn this case, the rule would also block other instances starting with “private” on your site, such as:
- https://yourwebsite.com/private.html
- https://yourwebsite.com/privateer
Therefore, it’s important to be precise. When in doubt, test your file.
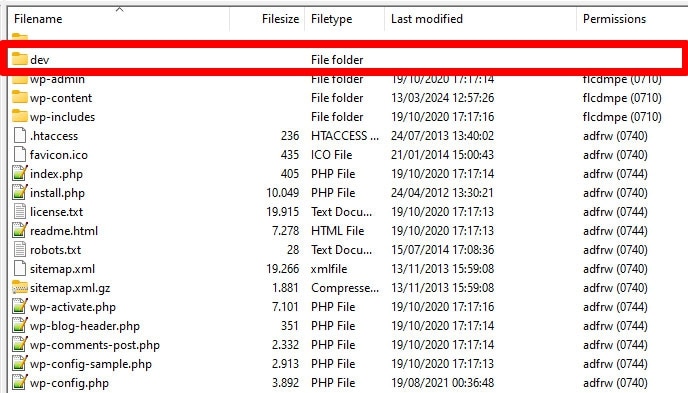
13. Missing robots.txt for Subdomains
Each subdomain on your website (e.g., dev.yourwebsite.com) needs its own robots.txt file because search engines treat them as separate web entities. Without a file in place, you risk crawlers indexing parts of your site you intended to keep hidden.
For example, if your development version is in a folder called “dev” and uses a subdomain, ensure that it has a dedicated robots.txt file to block search crawlers.
14. Not Testing Your robots.txt File
One of the biggest mistakes when configuring your WordPress robots.txt file is failing to test it, especially after making changes.
As we have seen, even small errors in syntax or logic can cause significant SEO issues. Therefore, always test your robots.txt file.
You can see any issues with your file in Google Search Console under Settings > robots.txt.
Another way is to simulate crawling behavior with a tool like Screaming Frog. Additionally, use a staging environment to verify the impact of new rules before applying them to your live site.
How to Recover From a robots.txt Error
Mistakes in your robots.txt file are easy to make, but fortunately, they’re also usually simple to fix once you discover them.
Start by running your updated robots.txt file through a testing tool. Then, if pages were previously blocked by robots.txt directives, manually input them into Google Search Console or Bing Webmaster Tools to request indexing.
Additionally, resubmit an up-to-date version of your sitemap.
After that, it’s just a waiting game. Search engines will revisit your site and, hopefully, restore your place in the rankings quickly.
Take Control of Your WordPress robots.txt
With robots.txt files, an ounce of prevention is better than a pound of cure. Especially on larger websites, a faulty file can wreak havoc on rankings, traffic, and revenue.
For that reason, any changes to your site’s robots.txt should be done carefully and with extensive testing. Awareness of the mistakes you can make is a first step in preventing them.
When you do make a mistake, try not to panic. Diagnose what’s wrong, correct any errors, and resubmit your sitemap to get your site re-crawled.
Finally, make sure performance isn’t the reason search engines don’t properly crawl your site. Try WP Rocket now to make your site faster instantly!


